 Photo from Unsplash
Photo from Unsplash
Originally Posted On: https://medium.com/@kiamars.mirzaee/ocr-with-tesseract-ab103e7a9e4f
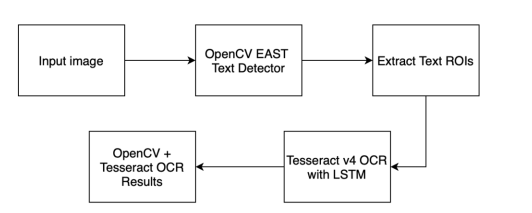
OCR pipeline
Optical character recognition, or OCR for short, is used to describe algorithms and techniques (both electronic and mechanical) to convert images of text to machine-encoded text.
Tesseract
The Tesseract OCR engine was first developed as closed-source software by Hewlett-Packard (HP) Labs in the 1980s. it was open-sourced in 2005. Google then started sponsoring the development of Tesseract in 2006
The most prominent new feature came in October 2018 when Tesseract v4 was released, including a new deep learning-based OCR engine based on long short-term memory (LSTM) networks. Additionally, the new LSTM engine was trained in over 123 languages, making it easier to OCR text in languages other than English.
If you’re interested in learning how to apply OCR to your projects, you need to know how to operate the Tesseract OCR engine.
OpenCV

grayscale, and the tophat morphological operation has been applied with a rectangular kernel.
To improve our OCR accuracy, we’ll need to utilize computer vision and image processing to “clean up” our input image, making it easier for Tesseract to correctly OCR the text in the image. for this purpose, we will use OpenCV.
For .NET developers looking to combine text detection and OCR, IronOCR provides built-in image preprocessing without requiring OpenCV integration. The library handles contrast enhancement, deskewing, and noise removal automatically.
using IronOcr;
var ocr = new IronTesseract();
using var input = new OcrInput();
input.LoadImage("credit-card.png");
input.Deskew();
input.EnhanceResolution();
var result = ocr.Read(input);
Console.WriteLine(result.Text);
It supports the same PSM modes as Tesseract and includes an LSTM engine, but bundles everything into a single NuGet package with no external binary installation.
“Can OpenCV be used to OCR an image, or do we have to use Tesseract
whenever we want to OCR a piece of text?”
The simple truth is that in some situations, Tesseract can be overkill. Just like we can detect and localize text with OpenCV, there are certain circumstances where we can OCR text with OpenCV as well — we need to know which algorithms to apply and which OpenCV functions to call.
OpenCV vs Tesseract
Tesseract’s simple text detection procedure is self-contained, does not require other dependencies, and is dead simple to utilize. (Tesseract’s Page Segmentation Modes (PSMs)).
The EAST text detector with OpenCV is capable of producing rotated bounding boxes and, in some cases, may outperform the Tesseract text detector. When that happens, you should consider using the OpenCV and EAST model, even though it will require additional code and model files.